Search
To search for an exact match, type the word or phrase you want in quotation marks.
A*DESK has been offering since 2002 contents about criticism and contemporary art. A*DESK has become consolidated thanks to all those who have believed in the project, all those who have followed us, debating, participating and collaborating. Many people have collaborated with A*DESK, and continue to do so. Their efforts, knowledge and belief in the project are what make it grow internationally. At A*DESK we have also generated work for over one hundred professionals in culture, from small collaborations with reviews and classes, to more prolonged and intense collaborations.
At A*DESK we believe in the need for free and universal access to culture and knowledge. We want to carry on being independent, remaining open to more ideas and opinions. If you believe in A*DESK, we need your backing to be able to continue. You can now participate in the project by supporting it. You can choose how much you want to contribute to the project.
You can decide how much you want to bring to the project.

With the increasing popularisation of artificial intelligence one term is making its way into our common vocabulary that —like the term “AI” itself— seems to mean different things to different people: the term “latent space.” As an artist who has been using AI in his practice for a long time, it is a term that has grown very close to my heart and, at least in my understanding of the processes that we commonly call “AI,” lies at their core. My interpretation of it is what also makes me confident enough to see artificial intelligence as a new medium and not merely as an advanced technical tool. In what follows I will try to give you some ideas of what “latent space” means to me and how I see, use and navigate it.
The correct way to talk about latent space would actually be to say latent spaces —the singular form can easily give the wrong impression that there is only a single one, a common space shared by all the artificial intelligences out there, like talking about the universe or cyberspace. In reality there are as many different latent spaces as there are models and neural architectures, nevertheless they share properties, behaviours and rules that allow us to apply the knowledge and techniques we learned in one space in any subsequent one we encounter later. In the same way as after we learned how to ride a bicycle or play the piano, at some point it does not matter anymore what the make of the vehicle or instrument is. This is why I will take the liberty to always talk about “latent space” in its singular form.
The difficulty of explaining latent space is that, like a black hole, it cannot be observed directly, but we can only get an idea about its shape and natural laws by observing how it interacts with its environment. This is also why I have to rely on metaphors and comparisons when describing the phenomena I encounter since we have not yet developed a common vocabulary or a taxonomy to communicate about them.
What is space? I only recently discovered Lázló Moholy-Nagy’s seminal book The New Vision (1928), which reads like a manifesto about the relationship between artist and space. His definition of space, which is derived from the physical definition is: “space is the position relation of bodies.” This captures exactly how I perceive latent space —the only difference is that instead of physical bodies, latent space is the position relation of information. This information can take many different forms depending on a model and the data it was trained on— it can be the meaning of words, the micro and macro structures of visual data, the encoding of sounds, the configurations of human poses —literally anything that permits itself to be translated into a digital form to be subsequently compressed and transformed into a multidimensional vector. These feature vectors or embeddings become the “bodies” that create latent space and their relations are the mathematical distances they have between them.
Whenever you arrange more than one body in a space you are creating an order and the question whether some of these configurations are superior to others is at the core of philosophical and aesthetical discourses. One criterion for the quality of an order is how unlikely it is and we instinctively recognize aesthetical arrangements by the fact that they do not appear random or “normal” to us —a “good” order is typically rare and in our experience does not form itself by accident, but rather as the result of an intentional effort or a keen curatorial eye. But how can we determine how unlikely a proposed order is compared to all other possible configurations of the same bodies? This requires measuring and summing up all the similarities of each body in a space to all its neighbours. Doing this for many different arrangements we can observe that the sums that we get will always follow a gaussian distribution —there will be a large central body of “average” sums which is where most of the arrangements are located that appear random or expected to us. At the same time there will be very few arrangements found at the outer ends of that curve that are unusual since their sums are either very large, which in the case of a similarity measure means that similar bodies have been placed as far away from each other as possible or very small. This we usually perceive as the most meaningful arrangement, since similar bodies have been placed as close together as the dimensions in the space they form allow.
Let me illustrate this with a very simple example: take the numbers from 1 to 6 —like you find them on a dice. There are 720 different ways you can arrange these numbers in a line, for example 4-2-5-6-1-3, 6-1-2-3-5-4, 1-2-3-4-5-6 or 3-6-5-1-4-2. Now why is it that 1-2-3-4-5-6 stands out from the other orders? Apart from the fact that we have learned in school that this is the natural order of numbers it can also be shown mathematically that this order is different from the rest: if you look at the differences of each number to their neighbours on their left and right, the sum for 425613 is 13, the one for 612354 is 10, 365142 is 13 as well, but for 123456 it is just 5. There is only one other arrangement among the 720 that is equally rare and that is the 6-5-4-3-2-1. Now it might appear very naive to claim that these laws derived from some simplified mathematical example do generalise to “… and this is how the world hangs together,” but this is exactly what I do. The difference between 123456 and the ability to distinguish a cat from a dog or to write a poem is mostly one of dimensionality.
The way in which models create a latent space is by trying to arrange everything they learn in a configuration that makes it the most probable and efficient in that, when queried about it later, they will give a most likely correct answer. And the most efficient arrangement to find something again is to put things closer together that share features —like in a library where you do not expect to look for poetry in the natural history shelf. One benefit neural networks have over libraries is that they have many more dimensions available —in a physical library you are limited to 3 dimensions and if you want to show related books together you can only put them on the same shelf, row, or department. And the moment you come across a book of poems about natural history, you have to make a hard decision or buy a second copy and put it in two departments. A neural network does not have that problem since it can make use of many more dimensions than just three —we are talking about hundreds or thousands of dimensions here. This allows models to construct spaces where relationships and similarities can be created on many different levels and which in a well trained model allow us to fluidly explore them on pathways that go beyond a taxonomy of established terms and categories.
As neural networks learn to optimise their predictions, they often end up creating abstract concepts that represent higher-level features in the data. For example, a network trained on images of animals might learn to recognize not only individual species but also more abstract concepts like “furry” or “striped.” These abstract concepts are not explicitly taught to the network, but emerge as part of the optimization process. In a text generation model like GPT-3 such an abstract concept could for example be “in the style of P.G. Wodehouse” for which we as humans would need a whole essay to describe what that entails, but to a neural network this can be represented as a vector that points along a multidimensional axis in that space and which allows to transform a given paragraph by preserving the meaning of the text but altering the vocabulary and sentence structures so it might remind the casual reader of the author’s signature style.
To me the most exciting aspect of working with latent spaces is that we are approaching the point where all kinds of media are being “understood” by these models and, just like in our brains, we will be able to freely move between different media and different modes of expression within a continuous fluid space in a form of synesthesia where a song can be transformed into a visual, that visual can be translated into a poem and the poem might turn into another song. Which means that learning to understand and play latent spaces will become one of the most versatile talents one can acquire.
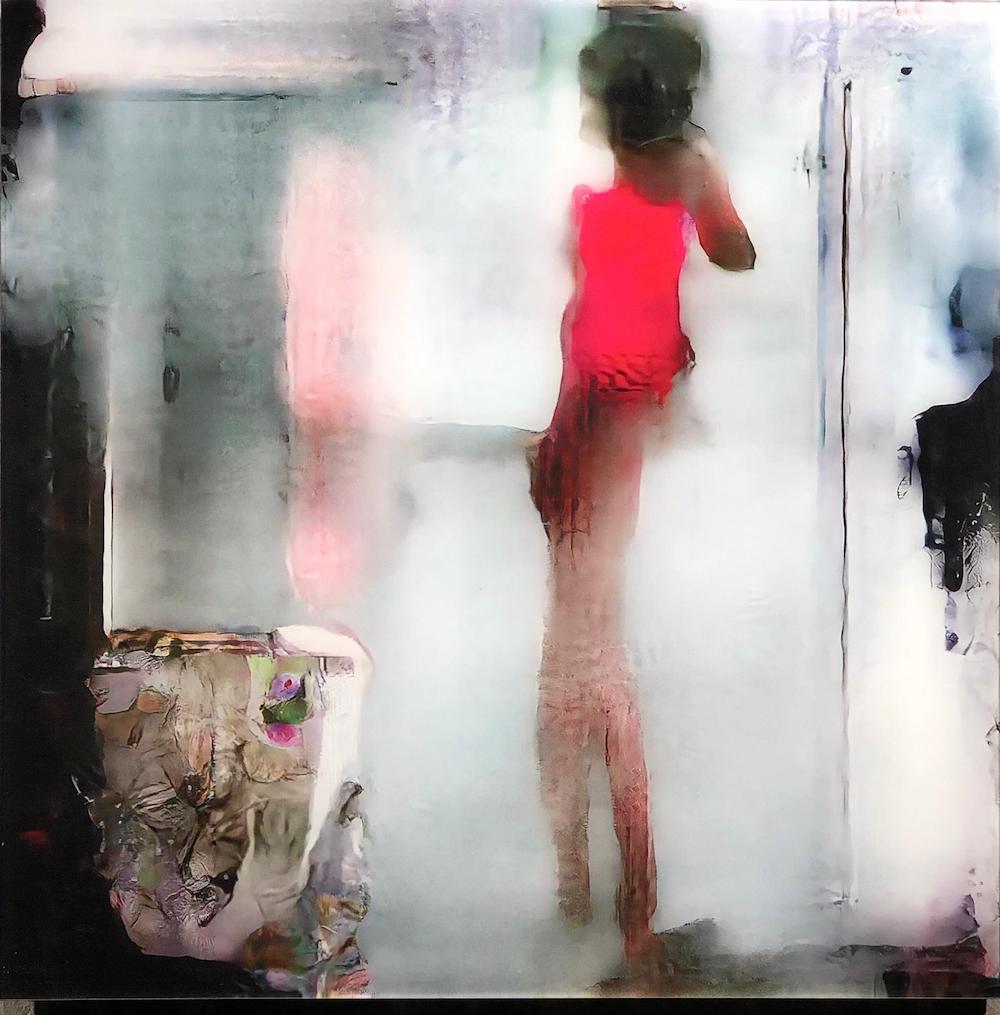
Neurography Standing ©MarioKlingemann. Courtesy Onkaos
(Front image: Mario Klingemann, Mitosis)

Self-described as “an artist and a skeptic with a curious mind,” Mario Klingemann creates art with neural networks, code and algorithms. His interests include artificial intelligence, deep learning, generative and evolutionary art, glitch art, data classification and visualization, and robotic installations. From 2016 to 2018 he was artist in residence at the Google Arts & Culture Lab. He received an honorary mention at the Prix Ars Electronica 2020 for his work “Appropriate Response”, the Artistic Award 2016 by the British Library Labs and won the Lumen Prize Gold 2018 for “The Butcher’s Son”.
www.quasimondo.com
Portrait: © Priscillia Grubo
Media Partners:



"A desk is a dangerous place from which to watch the world" (John Le Carré)